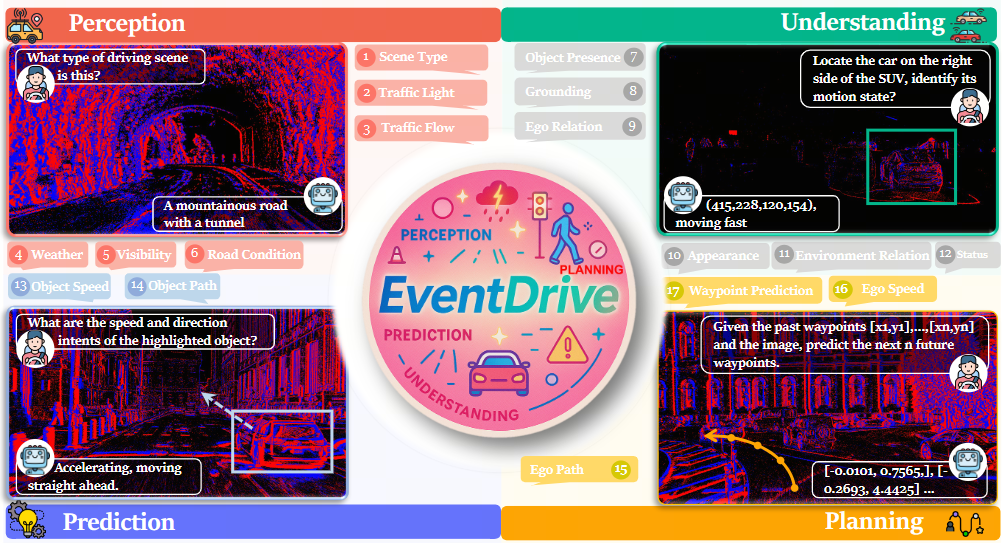
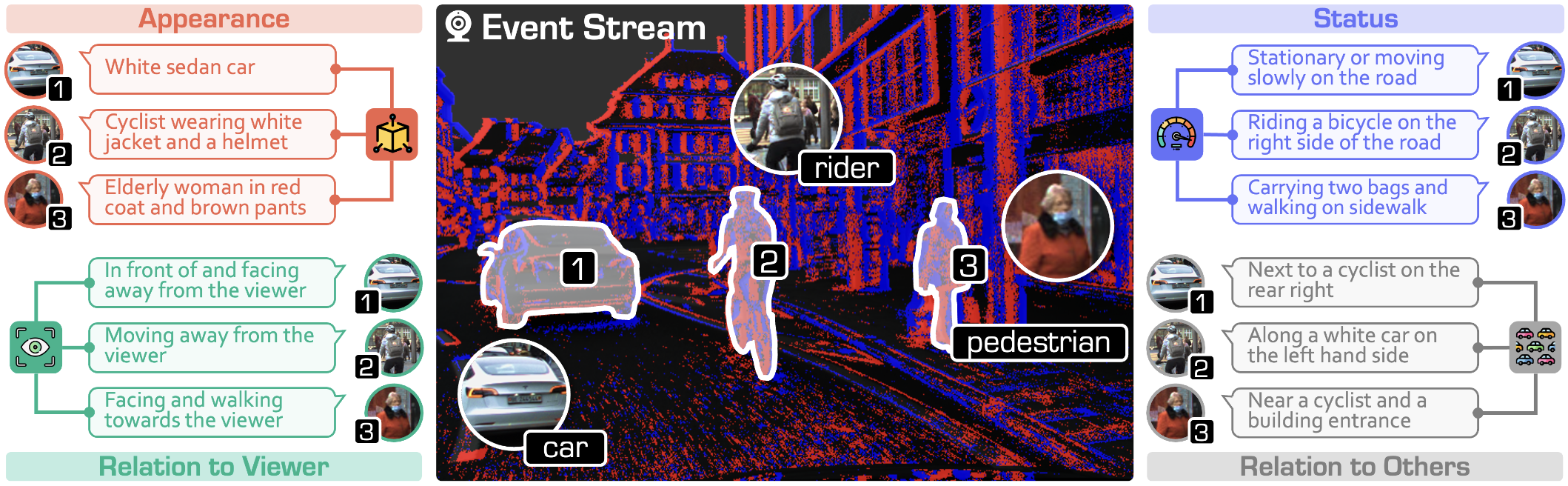
Dongyue Lu*, Ao Liang*, Tianxin Huang, Xiao Fu, Yuyang Zhao, Baorui Ma, Liang Pan, Wei Yin, Lingdong Kong, Wei Tsang Ooi, Ziwei Liu
Eurographics 2026
[Project] [Paper]
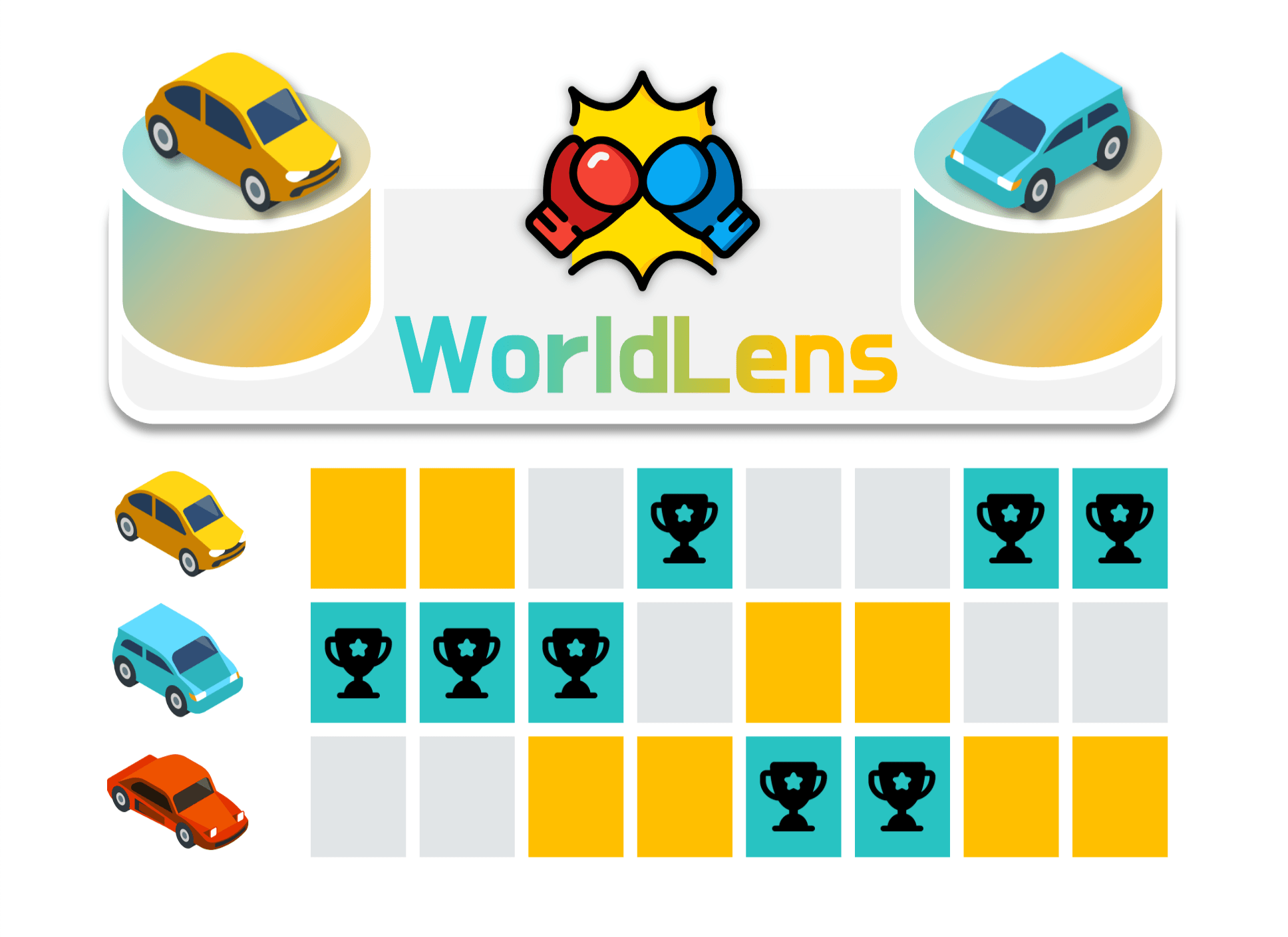
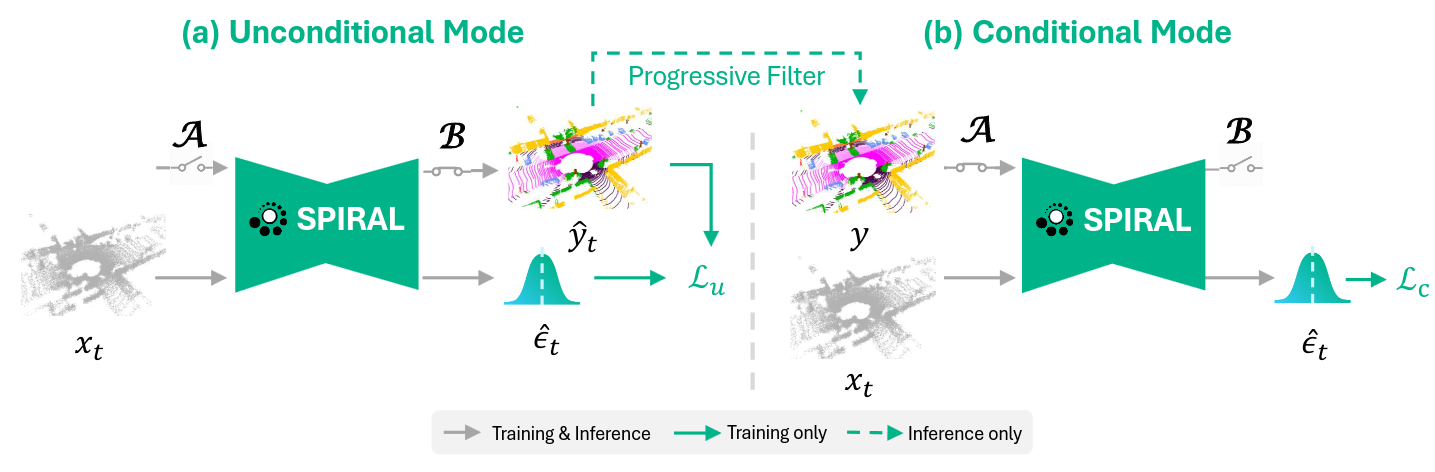
Dongyue Lu, Rong Li, Ao Liang, Lingdong Kong, Wei Yin, Lai Xing Ng, Benoit R. Cottereau, Camille Simon Chane, Wei Tsang Ooi
CVPR 2026
[Project] [Paper] [Data]
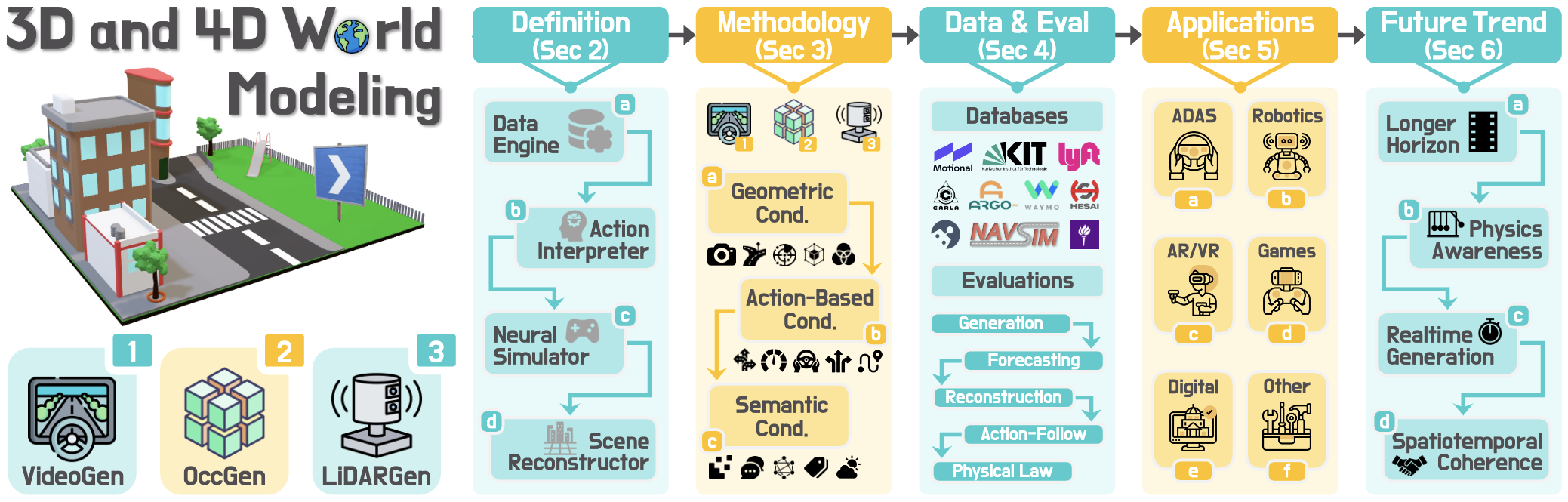
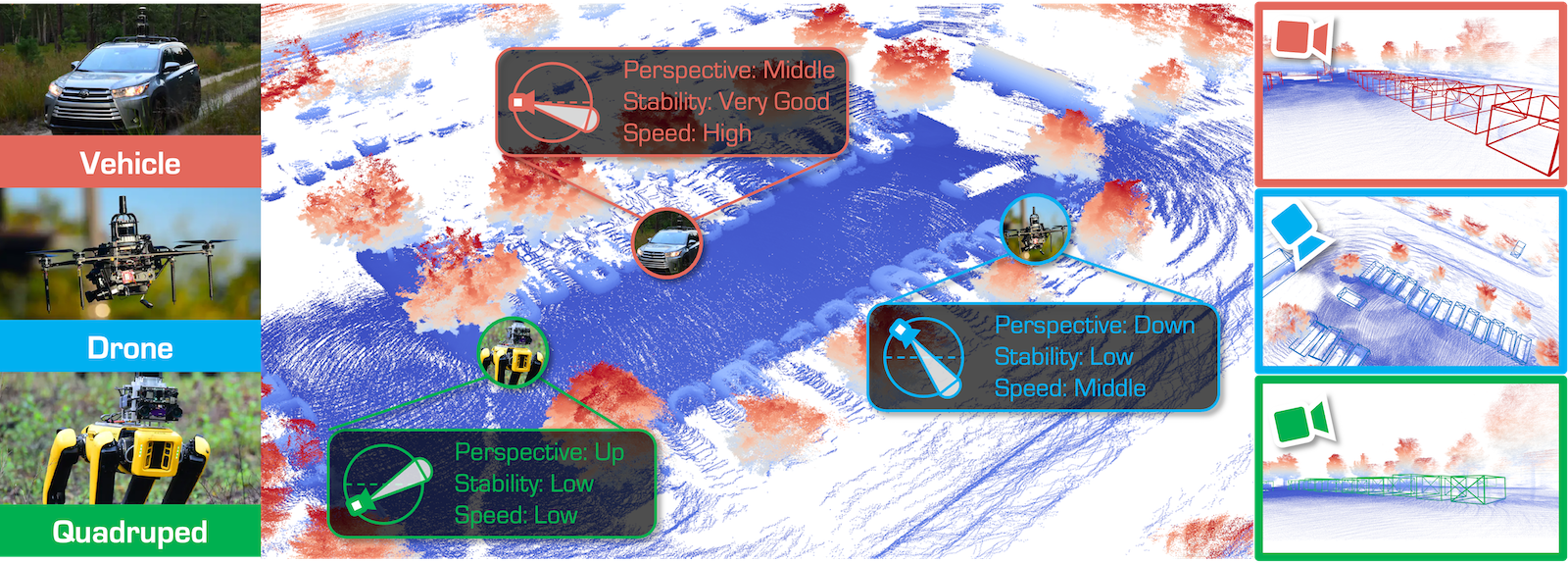
Ao Liang*, Lingdong Kong*, Tianyi Yan*, Hongsi Liu*, Wesley Yang*, ..., Dongyue Lu, et al.
CVPR, 2026 Oral
[Project] [Paper] [Code]
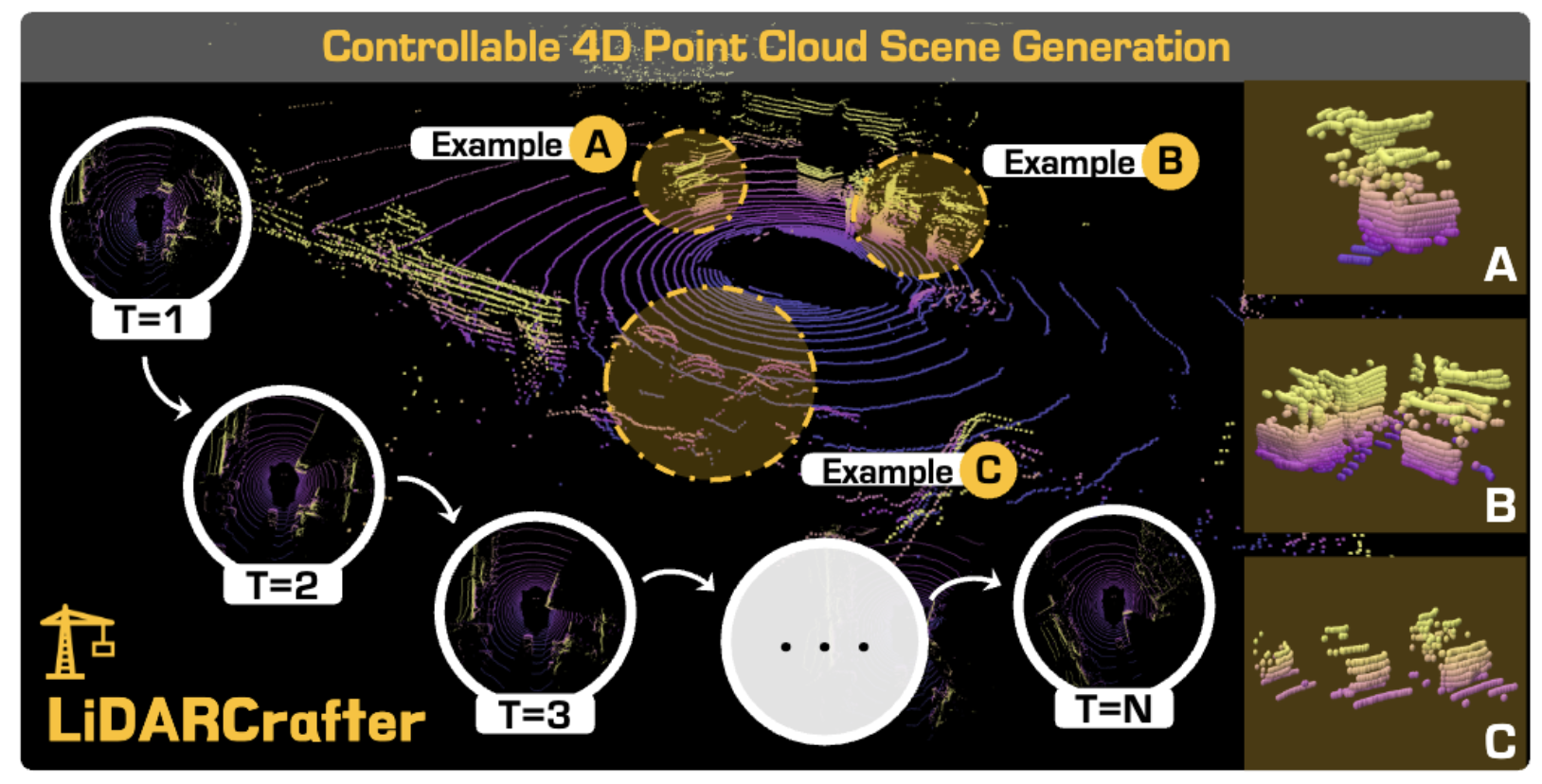
Lingdong Kong*, Wesley Yang*, Jianbiao Mei*, Youquan Liu*, Ao Liang*, Dekai Zhu*, Dongyue Lu*, Wei Yin*, et al.
arXiv, 2025
[Project] [Paper] [GitHub]
Ao Liang, Youquan Liu, Yu Yang, Dongyue Lu, Linfeng Li, Lingdong Kong, Huaici Zhao, Wei Tsang Ooi
AAAI, 2026 Oral
Dongyue Lu, Lingdong Kong, Gim Hee Lee, Camille Simon Chane, Wei Tsang Ooi
NeurIPS, 2025
Lingdong Kong*, Dongyue Lu*, Ao Liang*, Rong Li, Yuhao Dong, Tianshuai Hu, Lai Xing Ng, Wei Tsang Ooi, Benoit R. Cottereau
NeurIPS, 2025 Spotlight (3.2%)
Dekai Zhu, Yixuan Hu, Youquan Liu, Dongyue Lu, Lingdong Kong, Slobodan Ilic
Rong Li*, Yuhao Dong*, Tianshuai Hu*, Ao Liang*, Youquan Liu*, Dongyue Lu*, Liang Pan, Lingdong Kong, Junwei Liang, Ziwei Liu
NeurIPS (Datasets and Benchmarks Track), 2025
Ao Liang*, Lingdong Kong*, Dongyue Lu*, Youquan Liu, Jian Fang, Huaici Zhao, Wei Tsang Ooi
ICCV, 2025
Dongyue Lu, Lingdong Kong, Tianxin Huang, Gim Hee Lee
CVPR, 2025
[Project] [Paper] [Code] [Data]
Lingdong Kong, Dongyue Lu, Xiang Xu, Lai Xing Ng, Wei Tsang Ooi, Benoit R. Cottereau
Buzhen Huang, Chen Li, Chongyang Xu, Dongyue Lu, Jinnan Chen, Yangang Wang, Gim Hee Lee
Yingye Xin, Xingxing Zuo, Dongyue Lu, Stefan Leutenegger
ISMAR, 2023
[Project] [Paper] [Code] [Video]